Big data analytics (BDA) in supply chain management (SCM) is receiving a growing attention. This is due to the fact that BDA has a wide range of applications in SCM, including customer behavior analysis, trend analysis, and demand prediction. In this survey, we investigate the predictive BDA applications in supply chain demand forecasting to propose a classification of these applications, identify the gaps, and provide insights for future research. We classify these algorithms and their applications in supply chain management into time-series forecasting, clustering, K-nearest-neighbors, neural networks, regression analysis, support vector machines, and support vector regression. This survey also points to the fact that the literature is particularly lacking on the applications of BDA for demand forecasting in the case of closed-loop supply chains (CLSCs) and accordingly highlights avenues for future research.
Nowadays, businesses adopt ever-increasing precision marketing efforts to remain competitive and to maintain or grow their margin of profit. As such, forecasting models have been widely applied in precision marketing to understand and fulfill customer needs and expectations [1]. In doing so, there is a growing attention to analysis of consumption behavior and preferences using forecasts obtained from customer data and transaction records in order to manage products supply chains (SC) accordingly [2, 3].
Supply chain management (SCM) focuses on flow of goods, services, and information from points of origin to customers through a chain of entities and activities that are connected to one another [4]. In typical SCM problems, it is assumed that capacity, demand, and cost are known parameters [5]. However, this is not the case in reality, as there are uncertainties arising from variations in customers’ demand, supplies transportation, organizational risks and lead times. Demand uncertainties, in particular, has the greatest influence on SC performance with widespread effects on production scheduling, inventory planning, and transportation [6]. In this sense, demand forecasting is a key approach in addressing uncertainties in supply chains [7,8,9].
A variety of statistical analysis techniques have been used for demand forecasting in SCM including time-series analysis and regression analysis [10]. With the advancements in information technologies and improved computational efficiencies, big data analytics (BDA) has emerged as a means of arriving at more precise predictions that better reflect customer needs, facilitate assessment of SC performance, improve the efficiency of SC, reduce reaction time, and support SC risk assessment [11].
The focus of this meta-research (literature review) paper is on “demand forecasting” in supply chains. The characteristics of demand data in today’s ever expanding and sporadic global supply chains makes the adoption of big data analytics (and machine learning) approaches a necessity for demand forecasting. The digitization of supply chains [12] and incoporporation Blockchain technologies [13] for better tracking of supply chains further highlights the role of big data analytics. Supply chain data is high dimensional generated across many points in the chain for varied purposes (products, supplier capacities, orders, shipments, customers, retailers, etc.) in high volumes due to plurality of suppliers, products, and customers and in high velocity reflected by many transactions continuously processed across supply chain networks. In the sense of such complexities, there has been a departure from conventional (statistical) demand forecasting approaches that work based on identifying statistically meannignful trends (characterized by mean and variance attributes) across historical data [14], towards intelligent forecasts that can learn from the historical data and intelligently evolve to adjust to predict the ever changing demand in supply chains [15]. This capability is established using big data analytics techniques that extract forecasting rules through discovering the underlying relationships among demand data across supply chain networks [16]. These techniques are computationally intensive to process and require complex machine-programmed algorithms [17].
With SCM efforts aiming at satisfying customer demand while minimizing the total cost of supply, applying machine-learning/data analytics algorithms could facilitate precise (data-driven) demand forecasts and align supply chain activities with these predictions to improve efficiency and satisfaction. Reflecting on these opportunities, in this paper, first a taxonmy of data sources in SCM is proposed. Then, the importance of demand management in SCs is investigated. A meta-research (literature review) on BDA applications in SC demand forecasting is explored according to categories of the algorithms utilized. This review paves the path to a critical discussion of BDA applications in SCM highlighting a number of key findings and summarizing the existing challenges and gaps in BDA applications for demand forecasting in SCs. On that basis, the paper concludes by presenting a number of avenues for future research.
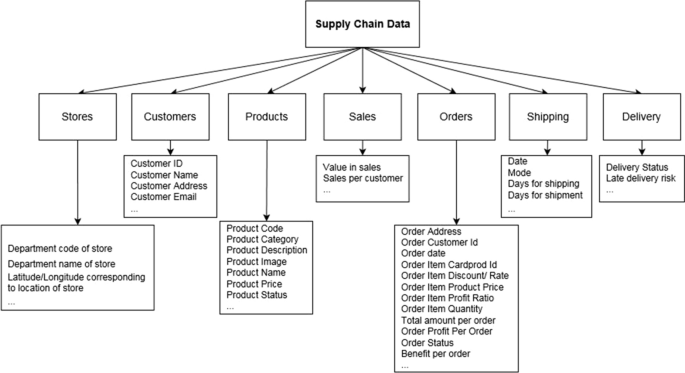
Data in the context of supply chains can be categorized into customer, shipping, delivery, order, sale, store, and product data [18]. Figure 1 provides the taxonomy of supply chain data. As such, SC data originates from different (and segmented) sources such as sales, inventory, manufacturing, warehousing, and transportation. In this sense, competition, price volatilities, technological development, and varying customer commitments could lead to underestimation or overestimation of demand in established forecasts [19]. Therefore, to increase the precision of demand forecast, supply chain data shall be carefully analyzed to enhance knowledge about market trends, customer behavior, suppliers and technologies. Extracting trends and patterns from such data and using them to improve accuracy of future predictions can help minimize supply chain costs [20, 21].
Analysis of supply chain data has become a complex task due to (1) increasing multiplicity of SC entities, (2) growing diversity of SC configurations depending on the homogeneity or heterogeneity of products, (3) interdependencies among these entities (4) uncertainties in dynamical behavior of these components, (5) lack of information as relate to SC entities; [11], (6) networked manufacturing/production entities due to their increasing coordination and cooperation to achieve a high level customization and adaptaion to varying customers’ needs [22], and finally (7) the increasing adoption of supply chain digitization practices (and use of Blockchain technologies) to track the acitivities across supply chains [12, 13].
Big data analytics (BDA) has been increasingly applied in management of SCs [23], for procurement management (e.g., supplier selection [24], sourcing cost improvement [25], sourcing risk management [26], product research and development [27], production planning and control [28], quality management [29], maintenance, and diagnosis [30], warehousing [31], order picking [32], inventory control [33], logistics/transportation (e.g., intelligent transportation systems [34], logistics planning [35], in-transit inventory management [36], demand management (e.g., demand forecasting [37], demand sensing [38], and demand shaping [39]. A key application of BDA in SCM is to provide accurate forecasting, especially demand forecasting, with the aim of reducing the bullwhip effect [14, 40,41,42].
Big data is defined as high-volume, high-velocity, high-variety, high value, and high veracity data requiring innovative forms of information processing that enable enhanced insights, decision making, and process automation [43]. Volume refers to the extensive size of data collected from multiple sources (spatial dimension) and over an extended period of time (temporal dimension) in SCs. For example, in case of freight data, we have ERP/WMS order and item-level data, tracking, and freight invoice data. These data are generated from sensors, bar codes, Enterprise resource planning (ERP), and database technologies. Velocity can be defined as the rate of generation and delivery of specific data; in other words, it refers to the speed of data collection, reliability of data transferring, efficiency of data storage, and excavation speed of discovering useful knowledge as relate to decision-making models and algorithms. Variety refers to generating varied types of data from diverse sources such as the Internet of Things (IoT), mobile devices, online social networks, and so on. For instance, the vast data from SCM are usually variable due to the diverse sources and heterogeneous formats, particularly resulted from using various sensors in manufacturing sites, highways, retailer shops, and facilitated warehouses. Value refers to the nature of the data that must be discovered to support decision-making. It is the most important yet the most elusive, of the 5 Vs. Veracity refers to the quality of data, which must be accurate and trustworthy, with the knowledge that uncertainty and unreliability may exist in many data sources. Veracity deals with conformity and accuracy of data. Data should be integrated from disparate sources and formats, filtered and validated [23, 44, 45]. In summary, big data analytics techniques can deal with a collection of large and complex datasets that are difficult to process and analyze using traditional techniques [46].
The literature points to multiple sources of big data across the supply chains with varied trade-offs among volume, velocity, variety, value, and veracity attributes [47]. We have summarized these sources and trade-offs in Table 1. Although, the demand forecasts in supply chains belong to the lower bounds of volume, velocity, and variety, however, these forecasts can use data from all sources across the supply chains from low volume/variety/velocity on-the-shelf inventory reports to high volume/variety/velocity supply chain tracking information provided through IoT. This combination of data sources used in SC demand forecasts, with their diverse temporal and spatial attributes, places a greater emphasis on use of big data analytics in supply chains, in general, and demand forecasting efforts, in particular.
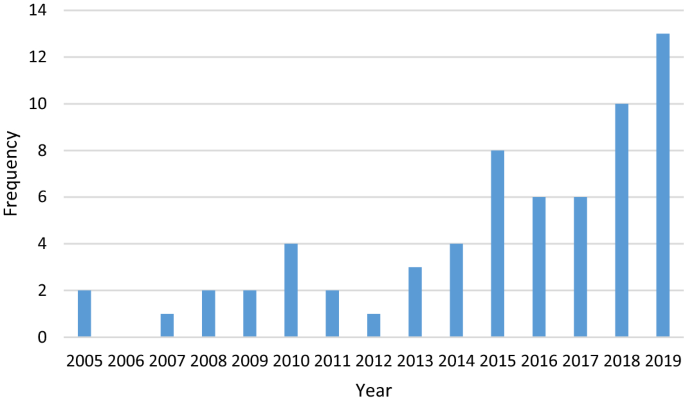
Table 2 Literature on BDA/machine learning techniques for supply chain demand forecasting (2005–2019)
It shall be mentioned that there are literature review papers exploring the use of big data analytics in SCM [10, 16, 23, 54,55,56,57,58,59,60,61,62,63,64,65,66,67]. However, this study focuses on the specific topic of “demand forecasting” in SCM to explore BDA applications in line with this particular subtopic in SCM.
As Hofmann and Rutschmann [58] indicated in their literature review, the key questions to answer are why, what and how big data analytics/machine-learning algorithms could enhance forecasts’ accuracy in comparison to conventional statistical forecasting approaches.
Conventional methods have faced a number of limitations for demand forecasting in the context of SCs. There are a lot of parameters influencing the demand in supply chains, however, many of them were not captured in studies using conventional methods for the sake of simplicity. In this regard, the forecasts could only provide a partial understanding of demand variations in supply chains. In addition, the unexplained demand variations could be simply considered as statistical noise. Conventional approaches could provide shorter processing times in exchange for a compromise on robustness and accuracy of predictions. Conventional SC demand forecasting approaches are mostly done manually with high reliance on the planner’s skills and domain knowledge. It would be worthwhile to fully automate the forecasting process to reduce such a dependency [58]. Finally, data-driven techniques could learn to incorporate non-linear behaviors and could thus provide better approximations in demand forecasting compared to conventional methods that are mostly derived based on linear models. There is a significant level of non-linearity in demand behavior in SC particularly due to competition among suppliers, the bullwhip effect, and mismatch between supply and demand [40].
To extract valuable knowledge from a vast amount of data, BDA is used as an advanced analytics technique to obtain the data needed for decision-making. Reduced operational costs, improved SC agility, and increased customer satisfaction are mentioned among the benefits of applying BDA in SCM [68]. Researchers used various BDA techniques and algorithms in SCM context, such as classification, scenario analysis, and optimization [23]. Machine-learning techniques have been used to forecast demand in SCs, subject to uncertainties in prices, markets, competitors, and customer behaviors, in order to manage SCs in a more efficient and profitable manner [40].
BDA has been applied in all stages of supply chains, including procurement, warehousing, logistics/transportation, manufacturing, and sales management. BDA consists of descriptive analytics, predictive analytics, and prescriptive analytics. Descriptive analysis is defined as describing and categorizing what happened in the past. Predictive analytics are used to predict future events and discover predictive patterns within data by using mathematical algorithms such as data mining, web mining, and text mining. Prescriptive analytics apply data and mathematical algorithms for decision-making. Multi-criteria decision-making, optimization, and simulation are among the prescriptive analytics tools that help to improve the accuracy of forecasting [10].
Predictive analytics are the ones mostly utilized in SC demand and procurement forecasting [23]. In this sense, in the following subsections, we will review various predictive big data analytics approaches, presented in the literature for demand forecasting in SCM, categorized based on the employed data analytics/machine learning technique/algorithm, with elaborations of their purpose and applications (summarized in Table 3).
Table 3 Literature on applications of predictive BDA in SC demand forecasting (2005 to 2019)Time series are methodologies for mining complex and sequential data types. In time-series data, sequence data, consisting of long sequences of numeric data, recorded at equal time intervals (e.g., per minute, per hour, or per day). Many natural and human-made processes, such as stock markets, medical diagnosis, or natural phenomenon, can generate time-series data. [48].
In case of demand forecasting using time-series, demand is recorded over time at equal size intervals [69, 70]. Combinations of time-series methods with product or market features have attracted much attention in demand forecasting with BDA. Ma et al. [71] proposed and developed a demand trend-mining algorithm for predictive life cycle design. In their method, they combined three models (a) a decision tree model for large-scale historical data classification, (b) a discrete choice analysis for present and past demand modeling, and (c) an automated time-series forecasting model for future trend analysis. They tested and applied their 3-level approach in smartphone design, manufacturing and remanufacturing.
Time-series approach was used for forecasting of search traffic (service demand) subject to changes in consumer attitudes [37]. Demand forecasting has been achieved through time-series models using exponential smoothing with covariates (ESCov) to provide predictions for short-term, mid-term, and long-term demand trends in the chemical industry SCs [7]. In addition, Hamiche et al. [72] used a customer-responsive time-series approach for SC demand forecasting.
In case of perishable products, with short life cycles, having appropriate (short-term) forecasting is extremely critical. Da Veiga et al. [73] forecasted the demand for a group of perishable dairy products using Autoregressive Integrated Moving Average (ARIMA) and Holt-Winters (HW) models. The results were compared based on mean absolute percentage error (MAPE) and Theil inequality index (U-Theil). The HW model showed a better goodness-of-fit based on both performance metrics.
In case of ARIMA, the accuracy of predictions could diminish where there exists a high level of uncertainty in future patterns of parameters [42, 74,75,76]. HW model forecasting can yield better accuracy in comparison to ARIMA [73]. HW is simple and easy to use. However, data horizon could not be larger than a seasonal cycle; otherwise, the accuracy of forecasts will decrease sharply. This is due to the fact that inputs of an HW model are themselves predicted values subject to longer-term potential inaccuracies and uncertainties [45, 73].
Clustering analysis is a data analysis approach that partitions a group of data objects into subgroups based on their similarities. Several applications of clustering analysis has been reported in business analytics, pattern recognition, and web development [48]. Han et al. [48] have emphasized the fact that using clustering customers can be organized into groups (clusters), such that customers within a group present similar characteristic.
A key target of demand forecasting is to identify demand behavior of customers. Extraction of similar behavior from historical data leads to recognition of customer clusters or segments. Clustering algorithms such as K-means, self-organizing maps (SOMs), and fuzzy clustering have been used to segment similar customers with respect to their behavior. The clustering enhances the accuracy of SC demand forecasting as the predictions are established for each segment comprised of similar customers. As a limitation, the clustering methods have the tendency to identify the customers, that do not follow a pattern, as outliers [74, 77].
Hierarchical forecasts of sales data are performed by clustering and categorization of sales patterns. Multivariate ARIMA models have been used in demand forecasting based on point-of-sales data in industrial bakery chains [19]. These bakery goods are ordered and clustered daily with a continuous need to demand forecasts in order to avoid both shortage or waste [19]. Fuel demand forecasting in thermal power plants is another domain with applications of clustering methods. Electricity consumption patterns are derived using a clustering of consumers, and on that basis, demand for the required fuel is established [77].
KNN is a method of classification that has been widely used for pattern recognition. KNN algorithm identifies the similarity of a given object to the surrounding objects (called tuples) by generating a similarity index. These tuples are described by n attributes. Thus, each tuple corresponds to a point in an n-dimensional space. The KNN algorithm searches for k tuples that are closest to a given tuple [48]. These similarity-based classifications will lead to formation of clusters containing similar objects. KNN can also be integrated into regression analysis problems [78] for dimensionality reduction of the data [79]. In the realm of demand forecasting in SC, Nikolopoulos et al. [80] applied KNN for forecasting sporadic demand in an automotive spare parts supply chain. In another study, KNN is used to forecast future trends of demand for Walmart’s supply chain planning [81].
In artificial neural networks, a set of neurons (input/output units) are connected to one another in different layers in order to establish mapping of the inputs to outputs by finding the underlying correlations between them. The configuration of such networks could become a complex problem, due to a high number of layers and neurons, as well as variability of their types (linear or nonlinear), which needs to follow a data-driven learning process to be established. In doing so, each unit (neuron) will correspond to a weight, that is tuned through a training step [48]. At the end, a weighted network with minimum number of neurons, that could map the inputs to outputs with a minimum fitting error (deviation), is identified.
As the literature reveals, artificial neural networks (ANN) are widely applied for demand forecasting [82,83,84,85]. To improve the accuracy of ANN-based demand predictions, Liu et al. [86] proposed a combination of a grey model and a stacked auto encoder applied to a case study of predicting demand in a Brazilian logistics company subject to transportation disruption [87]. Amirkolaii et al. [88] applied neural networks in forecasting spare parts demand to minimize supply chain shortages. In this case of spare parts supply chain, although there were multiple suppliers to satisfy demand for a variety of spare parts, the demand was subject to high variability due to a varying number of customers and their varying needs. Their proposed ANN-based forecasting approach included (1) 1 input demand feature with 1 Stock-Keeping Unit (SKU), (2) 1 input demand feature with all SKUs, (3) 16 input demand features with 1 SKU, and (4) 16 input demand features with all SKUs. They applied neural networks with back propagation and compared the results with a number of benchmarks reporting a Mean Square Error (MSE) for each configuration scenario.
Huang et al. [89] compared a backpropagation (BP) neural network and a linear regression analysis for forecasting of e-logistics demand in urban and rural areas in China using data from 1997 to 2015. By comparing mean absolute error (MAE) and the average relative errors of backpropagation neural network and linear regression, they showed that backpropagation neural networks could reach higher accuracy (reflecting lower differences between predicted and actual data). This is due to the fact that a Sigmoid function was used as the transfer function in the hidden layer of BP, which is differentiable for nonlinear problems such as the one presented in their case study, whereas the linear regression works well with linear problems.
ANNs have also been applied in demand forecasting for server models with one-week demand prediction ahead of order arrivals. In this regard, Saha et al. [90] proposed an ANN-based forecasting model using a 52-week time-series data fitted through both BP and Radial Basis Function (RBF) networks. A RBF network is similar to a BP network except for the activation/transfer function in RBF that follows a feed-forward process using a radial basis function. RBF results in faster training and convergence to ANN weights in comparison with BP networks without compromising the forecasting precision.
Researchers have combined ANN-based machine-learning algorithms with optimization models to draw optimal courses of actions, strategies, or decisions for future. Chang et al. [91] employed a genetic algorithm in the training phase of a neural network using sales/supply chain data in the printed circuit board industry in Taiwan and presented an evolving neural network-forecasting model. They proposed use of a Genetic Algorithms (GA)-based cost function optimization to arrive at the best configuration of the corresponding neural network for sales forecast with respect to prediction precision. The proposed model was then compared to back-propagation and linear regression approaches using three performance indices of MAPE, Mean Absolute Deviation (MAD), and Total Cost Deviation (TCD), presenting its superior prediction precision.
Regression models are used to generate continuous-valued functions utilized for prediction. These methods are used to predict the value of a response (dependent) variable with respect to one or more predictor (independent) variables. There are various forms of regression analysis, such as linear, multiple, weighted, symbolic (random), polynomial, nonparametric, and robust. The latter approach is useful when errors fail to satisfy normalcy conditions or when we deal with big data that could contain significant number of outliers [48].
Merkuryeva et al. [92] analyzed three prediction approaches for demand forecasting in the pharmaceutical industry: a simple moving average model, multiple linear regressions, and a symbolic regression with searches conducted through an evolutionary genetic programming. In this experiment, symbolic regression exhibited the best fit with the lowest error.
As perishable products must be sold due to a very short preservation time, demand forecasting for this type of products has drawn increasing attention. Yang and Sutrisno [93] applied and compared regression analysis and neural network techniques to derive demand forecasts for perishable goods. They concluded that accurate daily forecasts are achievable with knowledge of sales numbers in the first few hours of the day using either of the above methods.
SVM is an algorithm that uses a nonlinear mapping to transform a set of training data into a higher dimension (data classes). SVM searches for an optimal separating hyper-plane that can separate the resulting class from another) [48]. Villegas et al. [94] tested the applicability of SVMs for demand forecasting in household and personal care SCs with a dataset comprised of 229 weekly demand series in the UK. Wu [95] applied an SVM, using a particle swarm optimization (PSO) to search for the best separating hyper-plane, classifying the data related to car sales and forecasting the demand in each cluster.
Continuous variable classification problems can be solved by support vector regression (SVR), which is a regression implementation of SVM. The main idea behind SVR regression is the computation of a linear regression function within a high-dimensional feature space. SVR has been applied in financial/cost prediction problems, handwritten digit recognition, and speaker identification, object recognition, etc. [48].
Guanghui [96] used the SVR method for SC needs prediction. The use of SVR in demand forecasting can yield a lower mean square error than RBF neural networks due to the fact that the optimization (cost) function in SVR does not consider the points beyond a margin of distance from the training set. Therefore, this method leads to higher forecast accuracy, although, similar to SVM, it is only applicable to a two-class problem (such as normal versus anomaly detection/estimation problems). Sarhani and El Afia [97] sought to forecast SC demand using SVR and applied Particle swarm optimization (PSO) and GA to optimize SVR parameters. SVR-PSO and SVR-GA approaches were compared with respect to accuracy of predictions using MAPE. The results showed a superior performance by PSO in terms time intensity and MAPE when configuring the SVR parameters.
Some works in the literature have used a combination of the aforementioned techniques. In these studies, the data flow into a sequence of algorithms and the outputs of one stage become inputs of the next step. The outputs are explanatory in the form of qualitative and quantitative information with a sequence of useful information extracted out of each algorithm. Examples of such studies include [15, 98,99,100,101,102,103,104,105].
In more complex supply chains with several points of supply, different warehouses, varied customers, and several products, the demand forecasting becomes a high dimensional problem. To address this issue, Islek and Oguducu [100] applied a clustering technique, called bipartite graph clustering, to analyze the patterns of sales for different products. Then, they combined a moving average model and a Bayesian belief network approaches to improve the accuracy of demand forecasting for each cluster. Kilimci et al. [101] developed an intelligent demand forecasting system by applying time-series and regression methods, a support vector regression algorithm, and a deep learning model in a sequence. They dealt with a case involving big amount of data accounting for 155 features over 875 million records. First, they used a principal component analysis for dimension reduction. Then, data clustering was performed. This is followed by demand forecasting for each cluster using a novel decision integration strategy called boosting ensemble. They concluded that the combination of a deep neural network with a boosting strategy yielded the best accuracy, minimizing the prediction error for demand forecasting.
Chen and Lu [98] combined clustering algorithms of SOM, a growing hierarchical self-organizing mapping (GHSOM), and K-means, with two machine-learning techniques of SVR and extreme learning machine (ELM) in sales forecasting of computers. The authors found that the combination of GHSOM and ELM yielded better accuracy and performance in demand forecasts for their computer retailing case study. Difficulties in forecasting also occur in cases with high product variety. For these types of products in an SC, patterns of sales can be extracted for clustered products. Then, for each cluster, a machine-learning technique, such as SVR, can be employed to further improve the prediction accuracy [104].
Brentan et al. [106] used and analyzed various BDA techniques for demand prediction; including support vector machines (SVM), and adaptive neural fuzzy inference systems (ANFIS). They combined the predicted values derived from each machine learning techniques, using a linear regression process to arrive at an average prediction value adopted as the benchmark forecast. The performance (accuracy) of each technique is then analyzed with respect to their mean square root error (RMSE) and MAE values obtained through comparing the target values and the predicted ones.
In summary, Table 3 provides an overview of the recent literature on the application of Predictive BDA in demand forecasting.
The data produced in SCs contain a great deal of useful knowledge. Analysis of such massive data can help us to forecast trends of customer behavior, markets, prices, and so on. This can help organizations better adapt to competitive environments. To forecast demand in an SC, with the presences of big data, different predictive BDA algorithms have been used. These algorithms could provide predictive analytics using time-series approaches, auto-regressive methods, and associative forecasting methods [10]. The demand forecasts from these BDA methods could be integrated with product design attributes as well as with online search traffic mapping to incorporate customer and price information [37, 71].
Most of the studies examined, developed and used a certain data-mining algorithm for their case studies. However, there are very few comparative studies available in the literature to provide a benchmark for understanding of the advantages and disadvantages of these methodologies. Additionally, as depicted by Table 3, there is no clear trend between the choice of the BDA algorithm/method and the application domain or category.
Most data-driven models used in the literature consider historical data. Such a backward-looking forecasting ignores the new trends and highs and lows in different economic environments. Also, organizational factors, such as reputation and marketing strategies, as well as internal risks (related to availability of SCM resources), could greatly influence the demand [107] and thus contribute to inaccuracy of BDA-based demand predictions using historical data. Incorporating existing driving factors outside the historical data, such as economic instability, inflation, and purchasing power, could help adjust the predictions with respect to unseen future scenarios of demand. Combining predictive algorithms with optimization or simulation can equip the models with prescriptive capabilities in response to future scenarios and expectations.
The combination of forward and reverse flow of material in a SC is referred to as a closed-loop supply chain (CLSC). A CLSC is a more complex system than a traditional SC because it consists of the forward and reverse SC simultaneously [108]. Economic impact, environmental impact, and social responsibility are three significant factors in designing a CLSC network with inclusion of product recycling, remanufacturing, and refurbishment functions. The complexity of a CLSC, compared to a common SC, results from the coordination between backward and forward flows. For example, transportation cost, holding cost, and forecasting demand are challenging issues because of uncertainties in the information flows from the forward chain to the reverse one. In addition, the uncertainties about the rate of returned products and efficiencies of recycling, remanufacturing, and refurbishment functions are some of the main barriers in establishing predictions for the reverse flow [5, 6, 109]. As such, one key finding from this literature survey is that CLSCs particularly deal with the lack of quality data for remanufacturing. Remanufacturing refers to the disassembly of products, cleaning, inspection, storage, reconditioning, replacement, and reassembling. As a result of deficiencies in data, optimal scheduling of remanufacturing functions is cumbersome due to uncertainties in the quality and quantity of used products as well as timing of returns and delivery delays.
IoT-based approaches can overcome the difficulties of collecting data in a CLSC. In an IoT environment, objects are monitored and controlled remotely across existing network infrastructures. This enables more direct integration between the physical world and computer-based systems. The results include improved efficiency, accuracy, and economic benefit across SCs [50, 54, 110].
Radio frequency identification (RFID) is another technology that has become very popular in SCs. RFID can be used for automation of processes in an SC, and it is useful for coordination of forecasts in CLSCs with dispersed points of return and varied quantities and qualities of returned used products [10, 111,112,113,114].
The growing need to customer behavior analysis and demand forecasting is deriven by globalization and increasing market competitions as well as the surge in supply chain digitization practices. In this study, we performed a thorough review for applications of predictive big data analytics (BDA) in SC demand forecasting. The survey overviewed the BDA methods applied to supply chain demand forecasting and provided a comparative categorization of them. We collected and analyzed these studies with respect to methods and techniques used in demand prediction. Seven mainstream techniques were identified and studied with their pros and cons. The neural networks and regression analysis are observed as the two mostly employed techniques, among others. The review also pointed to the fact that optimization models or simulation can be used to improve the accuracy of forecasting through formulating and optimizing a cost function for the fitting of the predictions to data.
One key finding from reviewing the existing literature was that there is a very limited research conducted on the applications of BDA in CLSC and reverse logistics. There are key benefits in adopting a data-driven approach for design and management of CLSCs. Due to increasing environmental awareness and incentives from the government, nowadays a vast quantity of returned (used) products are collected, which are of various types and conditions, received and sorted in many collection points. These uncertainties have a direct impact on the cost-efficiency of remanufacturing processes, the final price of the refurbished products and the demand for these products [115]. As such, design and operation of CLSCs present a case for big data analytics from both supply and demand forecasting perspectives.
The paper presents a review of the literature extracted from main scientific databases without presenting data.
Adaptive neural fuzzy inference systems
Auto regressive integrated moving average
Artificial neural network
Big data analytics
Closed-loop supply chain
Extreme learning machine
Enterprise resource planning
Growing hierarchical self-organizing map
Internet of things
Mean absolute deviation
Mean absolute error
Mean absolute percentage error
Mean square error
Mean square root error
Radial basis function
Particle swarm optimization
Supply chain analytics
Supply chain management
Support vector machine
Support vector regression
Total cost deviation
Theil inequality index
The authors are very much thankful to anonymous reviewers whose comments and suggestion were very helpful in improving the quality of the manuscript.